SAP HANA: Technologie in-memory databázové platformy
Článek pojednává o technologických aspektech in-memory databázových platforem, konkrétně pak na příkladu produktu SAP HANA. Objasňuje hlavní rysy jeho funkčnosti a přináší detailní popis zpracování dat prostřednictvím in-memory technologií. 1. Proč vznikly databázové platformy s technologií in-memory computingu? Hlavním důvodem, proč vznikly in-memory databázové platformy, byla nutnost reagovat na potřebu zpracování stále se navyšujícího objemu podnikových dat. Tato data slouží nejen k transakcím v provozních systémech typu ERP nebo CRM. Stále častěji se objevují požadavky od podnikových analytiků a vrcholových manažerů na rychlé zpracování analytických dotazů a dolování znalostí v rozsáhlých databázových strukturách, které by byly použitelné k podpoře rozhodování na strategické úrovni organizací nejrůznějších typů a velikostí. Dále je třeba brát v úvahu, že historické rozdělení databázových systémů na OLAP a OLTP již často neodpovídá jejich současné povaze. Rozdíly mezi oběma koncepty se totiž do značné míry setřely. V OLTP systémech stále více převažují "read-only" dotazy. Druhým problémem je pak stále se prodlužující čas, který je potřebný pro ETL fázi mezi OLTP a OLAP, nehledě na to, že během ETL procesu dochází ke ztrátě části informací v důsledku agregací. V neposlední řadě tu pak máme duplicitní data, plynoucí z tohoto rozdělení. Vezměme jako příklad společnost, jejíž hlavní činností je výroba, prodej a servis zemědělských strojů, která se rozhodla pro zavedení databázové platformy běžící v operační paměti. Pokud si uvědomíme, že každý traktor, kombajn nebo jiné složitější mechanické zařízení je doslova poseté čipy, zaznamenávající stav nejdůležitějších součástek, jistě si dovedeme představit, že zpracovávat takto získaná data pro stovky zákazníku, majících pronajatých tisíce strojů, by znamenalo, že dříve dojde k samotné poruše, než se zanalyzují výstupy z příslušných senzorů. Díky systému, jako je např. SAP HANA, správnému uložení a sběru dat, lze data procházet a vyvozovat z nich možné problémy s předstihem, vyměnit tak rizikové součásti a vyhnout se placení pokut za traktory, které zůstanou stát s defektem uprostřed pole v období sklizně. 2. Perzistence První věc, která člověka nejspíše napadne ohledně operační paměti, je bezpečnost uložení dat. Co se stane, když dojde k výpadku proudu (pokud nemáme UPS) nebo poruše jednoho z modulů paměti serveru? Nepřijdu o část svých dat? Jak dlouho bude trvat zotavení? Samozřejmě ani u in-memory databázových platforem se neobejdeme bez klasických nebo SSD disků. SAP HANA v základním nastavení každých 5 minut vytváří tzv. "savepoint" na pevné disky a k tomu neustále zapisuje transakční změny do logů, jako je tomu u ostatních databází, stejně tak na perzistentní úložiště (některý výrobce SAP HANA kompatibilního hardwaru používají speciální flash karty, jiní například SSD disky). Vytváření těchto savepointů není jen prosté zapsání kompletního obsahu paměti na disky. V takovém případě bychom zcela ztráceli rychlost a výhody, pokud bychom museli čekat na zapsání. Proto se do těchto obrazů zapisují pouze změny od posledního obrazu a to asynchronně. V případě poruchy a následného restartu (za předpokladu, že jsme nepřišli o disky) se nejprve načte poslední savepoint a pak se zrekonstruují transakce z logů zapsaných od posledního savepointu do času poruchy. Obr. 1 – SAP HANA perzistence (Zdroj: Bachmaier, Krutov, 2014)
3. Column-based tabulky Protože většina analytických dotazů sleduje data pouze některých atributů tabulky, vznikl koncept sloupcového uložení. K operační paměti totiž přistupujeme sekvenčně, čili data jsou zapsána v řadě za sebou a čteme je po částech o velikosti dané velikostí cache. Vezměme například tabulku zaměstnanců nadnárodní organizace se sto tisíci zaměstnanci. Pokud by nás zajímal počet mužů, museli bychom v row-store tabulce projít celou tabulku a načíst postupně všechny záznamy a jejich atributy. V případě column-based tabulky stačí přečíst pouze sloupec s pohlavím a sečíst počet výskytu mužů. Tab. 1 – Rozdíl mezi column a row based tabulkou (Zdroj: vlastní zpracování)
4. Komprese dat Pokud jsme v předchozím případě hovořili o potřebném jednom bytu pro zaznamenání pohlaví pracovníka, ve skutečnosti si zde vystačíme s pouhým bitem. Pro sloupcové tabulky se totiž používá slovníková komprese jako defaultní pro každý sloupec. Jestliže se totiž podíváme na data v podnikových tabulkách téměř jakýchkoli systémů (ERP, CRM, SCM), zjistíme, že mnoho sloupců má velmi nízkou kardinalitu. Některé sloupce dokonce nejsou využity vůbec, nebo obsahují pouze jednu hodnotu. Proto je vhodné data reprezentovat jinak než pomocí znaků abecedy, slov nebo názvů. Ukažme si na příkladu, jak taková slovníková komprese funguje. Pokud uvažujeme znovu naši tabulku zaměstnanců, sloupec oddělení bude mít pravděpodobně pouze několik odlišných hodnot. Řekněme, že firma má pět divizí. Pro tento atribut se tedy vytvoří slovník, kde bude abecedně seřazený seznam divizí ve slovní podobě a ke každé divizi bude přiřazeno jedno číslo počínaje nulou. V samotném sloupci pak nebude slovní popis oddělení, ale pouze číslo odkazující se na slovník. Pro pět divizí tedy potřebujeme pouhé dva bity pro reprezentaci přiřazení pracovníka místo původních padesáti bytů (pokud bychom uvažovali 50 znaků pro název oddělení). Na sto tisíci záznamech to již může dělat značný rozdíl. Obecně se počítá při migraci zákaznických BW systémů s faktorem komprese 6-8x. Obr. 2 – Slovníková komprese (Zdroj: vlastní zpracování)
Kromě ušetřeného místa v paměti a na disku se zrychlí vyhledávání, protože porovnáváme čísla místo znaků (práce s čísly je pro procesor a s ním spojené části a registry mnohem snazší) a navíc v seřazeném slovníku je možno použít binární vyhledávání místo sekvenčního. Mimoto jak na atribut vektor, tak na slovník se dá uplatnit další z řady sekundárních kompresí, jako jsou například run-length algoritmus, prefix encoding, cluster encoding a jiné (SAP HANA dokáže sama prohlédnutím hodnot vybrat nejlepší algoritmus a uplatnit ho). Tyto výhody jsou ovšem vykoupeny faktem, že pokud by v našem příkladu firmy přibyla další divize, která by byla alfabeticky před divizí "vedení", museli bychom přeskládat slovník a poté projít všech sto tisíc záznamů a poupravit ID hodnoty 5. Hlavní a delta úložiště Problém s přidáváním nových hodnot do slovníku atributu řeší SAP HANA pomocí rozdělení každé tabulky na main a delta storage. Jestliže by toto rozdělení neexistovalo, musel by se jak slovník, tak atribut vektor kompletně přeskládávat velmi často. U tabulek se stovkami milionů záznamů, které se v praxi běžně vyskytují, by to znamenalo značné zpomalení práce s databází. Proto veškeré změny (delete, insert, update) jsou zaznamenávány nejprve do delty, která má vlastní vektory atributů a slovníky pro každý sloupec tabulky. Pokaždé, když tedy měníme nějaký záznam, je tento nejprve označen jako invalidní v hlavní části a poté zapsán jako nový v deltě. Stejně tak operace delete neprobíhá tak, že bychom opravdu záznam fyzicky smazali, pouze se označí jako invalidní a teprve při operaci zvané delta merge dochází k "housekeepingu". Naproti tomu, pokud zadáme selektivní dotaz, procházíme pro získání výsledku jak delta, tak i main storage. Čímž projdeme všechny záznamy a dostaneme korektní odpověď. Obr. 3 – Rozdělení úložišť tabulky (Zdroj: vlastní zpracování)
5.1 Delta merge Čas od času je potřeba spojení obou úložišť tabulky, protože čím větší by byla delta, která je optimalizovaná hlavně pro zápis, díky užití různých verzí binárního stromu (B+ tree, CSB+), tím vyšší by byl čas pro vyhledávání, čímž bychom přišli o hlavní výhodu in-memory databázových platforem. Delta merge může být aktivován při různých událostech. Při určitém počtu záznamů v deltě, určité velikosti delty v paměti, poměrové velikosti k hlavnímu úložišti nebo lze merge proces spouštět manuálně. Existuje speciální varianta, kdy je spojení iniciováno aplikací po provedení určité akce, což se hodí například pokud probíhají objemné loady, během nichž by jinak došlo k několikanásobnému sloučení. Během delta merge operace můžeme zároveň spouštět sekundární kompresi, pokud je pro tabulku zapnutá. Vše lze nastavit v hlavních konfiguračních souborech SAP HANA. 6. SAP HANA procesy Stejně jako ostatní databáze, i SAP HANA se skládá z několika běžících procesů. Každý z nich slouží jednomu hlavnímu účelu a většinou má několik dalších menších úkolů. V případě scale-out řešení, kde je jeden master, několik worker a případně jeden nebo více stand-by nodů, jsou některé procesy pouze na master nodu. Proto si popíšeme ty, které jsou přítomny právě na hlavním serveru. Kromě těchto hlavních procesů na serveru běží další podpůrné jako saphostcontrol a sapstartsrv, které slouží pro vzdálenou správu a monitoring ostatních procesů, a nebo web dispatcher, jehož hlavní funkcí je distribuce http/https requestů pro xsengine. 7. Závěr SAP HANA a jiné in-memory databázové platformy jsou budoucností všech podnikových informačních systémů. SAP nedávno uvolnil informaci o novém produktu, který bude již v základu optimalizován pro tuto technologii. Produkt se jmenuje SAP Business Suite 4 SAP HANA nebo zkráceně SAP S/4 HANA. Společnost SAP k tomu uvedla, že se jedná o největší pokrok od dob SAP R/3. Možnosti personalizace, které budou zákazníkům v rámci tohoto řešení nabízeny, skýtají jak klasickou verzi se zakoupenými servery, tak cloudovou nebo hybridní verzi. Proto kromě systémů BW, ECC a role akcelerátoru, kde může nyní HANA být použita jako databázový systém, budou všechny systémy na bázi SAP optimalizovány pro in-memory technologii.
Použitá literatura 15.04.2015 - Petr Svitálek - četlo 45329 čtenářů.
(Klikněte na obrázek pro zvětšení)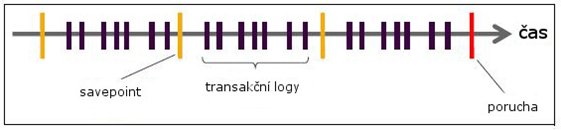
(Klikněte na obrázek pro zvětšení)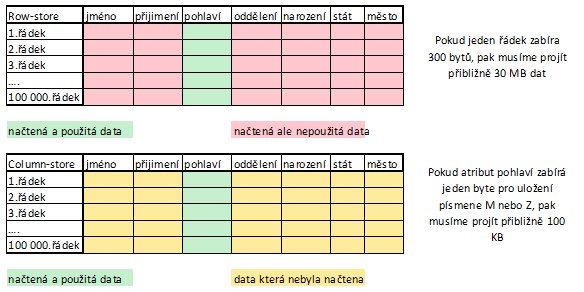
(Klikněte na obrázek pro zvětšení)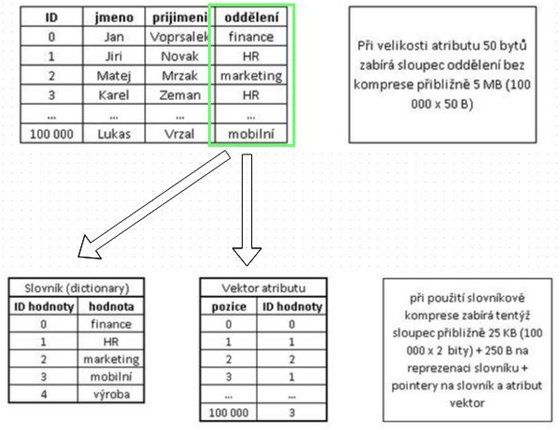
(Klikněte na obrázek pro zvětšení)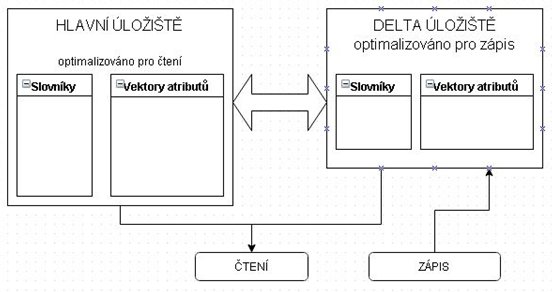
| Tento článek ješte není ohodnocen. | Hodnocení článku: nejlepší [ 1 | 2 | 3 | 4 | 5 ] nejhorší |
| Jméno | ||
| Opište kód : | |
|
| Text *) |
||
|
|
|


